
pythonのスクレイピングモジュールrequestsについて説明します。
この記事を理解するには以下の前提条件が必要となります。
- python3の基礎構文を理解していること。
- CUIでlinuxのファイル操作ができること。
- wsl環境またはunix環境であること。
また実行環境は以下の通りです。
| OS | 実行環境 | 使用言語 | python環境 |
| windows11 | WSL2(Windows Subsystem for Linux 2) | python3 | venv |
スクレイピングとは?
そもそもスクレイピングとは?
ネット上に公開された情報を、プログラムを用いて自動で集めることができます。このネット情報を自動で取集することをクローリングといいます。
集めたデータはそのままでは使えないことも多いです。そのデータを解析し、必要なデータを取得することをスクレイピングといいます。
requestsをインストール
requestsモジュールを使用し、簡単にpythonでインターネットに接続し情報を取得することができます。
さっそくモジュールをインストールしましょう。今回の前提条件として下記の環境で使用します。
まずvenvをpip作成コマンドで作成。
python3 -m venv venvvenvを実行
source venv/bin/activate続いてrequestsモジュールをpipコマンドでインストールします。
pip install requestsこれで環境ができました。
requestsの主なコマンド
requestsに以下のコマンドが使用可能です。
| コマンド | 内容 |
| requests.get(“url”) | 指定したURLを取得 |
| .apparent_encding | 文字化けしないように自動的に文字コードを調整 |
| .text | 文字列データを取得 |
| .content | バイナリデータを取得 |
| .url | アクセスしたurlを取得 |
| .status_code | HTTPステータスコードを取得 |
| .headers | レスポンスヘッダーを取得 |
それでは実際にコードを書いていきましょう!…と言いたいところですが、その前に注意事項があります。
注意事項
まず1つ目は、Reactのようにjsでレンダリングされた動的サイトではうまく取得できません。その場合は、selenuimという別モジュールが必要になります。
次に、現在多くのウェブサイトではスクレイピングが禁止されていることが多いです。
まずスクレイピングしたいURL先が許可しているかの利用規約などを確認をします。とくにxやnoteなどのニュース系サイトでは明確に禁止しています。訴訟などのリスクがあるので注意してください。
簡単に確認する方法としてrobots.txtを確認する方法があります。
今回はQiitaで確認していきます。robots.txtの確認方法はサイトURLの末尾にrobots.txtと追加すると見れることがほとんどです。
URLサーチ欄にhttps://qiita.com/robots.txtと入力します。
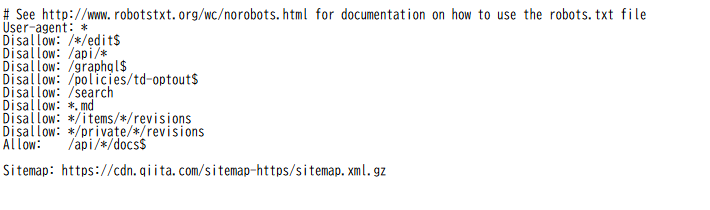
すると以下のようにrobots.txtが表示されます。
読み方
| Use-agent: | クローラー名 |
| Disallow: | アクセスを禁止するパス |
| Allow: | アクセスを許可するパス |
| Sitemap: | サイトマップのURL(検索エンジン向け) |
要約
User-agent: * ← 全てのクローラーに適用(Googlebot、Bingbotなど全部)
Disallow: //edit$ ← URLの末尾が「/edit」のページはクロール禁止 Disallow: /api/ ← /api/ で始まるすべてのURLは禁止
Disallow: /graphql$ ← URLが「/graphql」で終わるページは禁止
Disallow: /policies/td-optout$ ← 指定されたURLは禁止
Disallow: /search ← /search で始まるページは禁止(検索ページかな)
Disallow: *.md ← 拡張子が .md のファイルはすべて禁止
Disallow: */items/*/revisions ← リビジョン履歴ページは禁止
Disallow: */private//revisions ← プライベートなリビジョン履歴ページも禁止 Allow: /api//docs$ ← ただし /api/〇〇/docs 形式のURLは例外的にOK
Sitemap: https://cdn.qiita.com/sitemap-https/sitemap.xml.gz ← サイトマップの場所
Qiitaでは、サイトのTOPページは許可しているようです。では早速、コードを書いていきます。
requestsを実行
import requests
url = "https://qiita.com/"
html = requests.get(url)
text_html = html.apparent_encoding
print(html.text)
なにをしているかひとつずつ解説します。
import requestsrequestsモジュールをインポートしています。これがないと始まりません。
url = "https://qiita.com/"変数にurlを代入しています。別に代入ぜず、そのままrequests.getに代入しても可能性です。
html = requests.get(url)ここでrequestsを使いurl情報を取得し、変数に代入。
text_html = html.apparent_encoding念のため文字化け対策。
print(html.text).textを使い取得情報を呼び出します。
実行結果
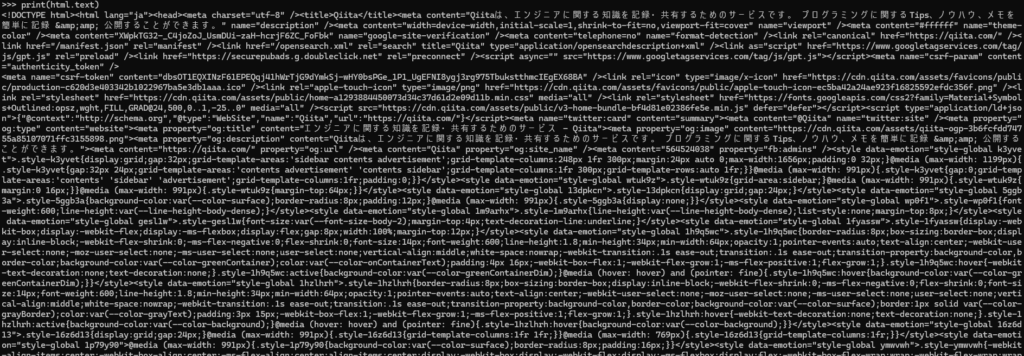
お気づきかと思いますがrequestsではHTMLすべて出力されてします。次回は、ここから欲しい情報を抜き取る方法を記事にします。今回はここまで、お疲れ様です。
コメント